

2022年底ChatGPT的横空出世,带来了AI大模型的热潮,一个全新的AI时代的到来,有人欣喜,有人焦虑,有人跃跃欲试。每一个新技术时代的到来,先知先行者总是能第一批吃到红利,那我们企业、个人甚至孩子该如何拿到AI大模型的船票呢?
一年多来技术层面AI大模型还在高歌猛进,捷报频传,但AI大模型如何在企业落地并真正发挥生产力,却尴尬地面临着无数的问题。
为什么令企业老板感到振奋积极拥抱的大模型,却频频遭到基层员工的嫌弃,迟迟无法发挥效果?如何才能让员工真正了解大模型、用好大模型?
如何让有着强大推理能力、掌握良好通识知识的AI大模型做好进入企业的在职培训,让它充分发挥生产力,提升我们的工作效率?
今天,明略科技创始人吴明辉先生作客混沌学园,为大家带来精彩一课,《AI如何赋能职场人——大模型落地企业方》。
2022年,当我在北大写博士论文的时候,才发现自己的综合资格考试报告白写了,很多知识都发生了更新。今天在读的AI领域博士非常惨,因为以往全世界所有从事人工智能一年的工作量,都不及今天一周的工作量大,大家如果不抓紧做出课题发表出去,基本上没有毕业的机会。

今天,我要同大家分享很重要的一个观点,就是不要着急。计算机刚刚出现的时候,每个人都说要从娃娃抓起,那时大家就很焦虑。事实上,我身边许多在世界500强企业工作的CEO,几乎都是跟我同龄时期才开始写代码的。所以,每一项新技术的出现都是有红利的,最终大家也一定都会使用到,只是接触早的人会比别人多一些机会和时间。如同《异类》一书中提出的1万小时定律,只要比别人多花一些时间做某件事情,未来就有机会享受到某领域的竞争红利。
我创办的公司名为明略科技,早期叫做秒针系统,是我在北大读研究生时候创办的,开始是做互联网大数据的用户分析,后来转型做广告分析。我们是国内最早用分布式计算系统处理海量用户行为的数据公司,这也成就了今天我们在国内互联网广告数据分析的江湖地位。

大家都很熟悉彭博社,彭博社是全世界最大的金融信息服务商,而秒针是中国最大的广告领域信息服务商,两者颇有渊源。彭博社的创始人迈克尔·布隆伯格创业初期,立志将电脑卖个每一位投资基金,希望帮助大家快速地获取互联网上的金融信息,这也成就了彭博社今天在全球金融信息服务领域的霸主地位。所以,很多公司都在拥抱新技术,它们可能是将某一项新技术用到了极致,或者是第一个使用新技术从而颠覆了上一代产品,最终走出了新的曲线。

为什么要研究大模型?因为这是当下最大的机会,这是我的切身感受。明略科技在过去十几年时间里发展的很顺利,但是过去三年中,资本市场发生了非常大的变化,整个商业逻辑也发生了改变,我们不得以也得裁员。2023年一年时间里,我每天都在思考如何带领团队突破困局,如何提升士气,在我面前非常大的一个机会就是大模型。
我们团队研究大模型也经历了非常曲折的过程。开始的时候我每天看Paper,然后转发到员工群中,大家的反映很平常,时间一长甚至没有人回应了。有一天我突然意识到,天天喊大模型是没有用的,我自己都没有真正地用好大模型,所以我注册了GPT,开始真正使用大模型,并带领团队做了一个能够帮助大家更好使用GPT的小工具,叫做“小明助理”,员工使用后的反响非常好。
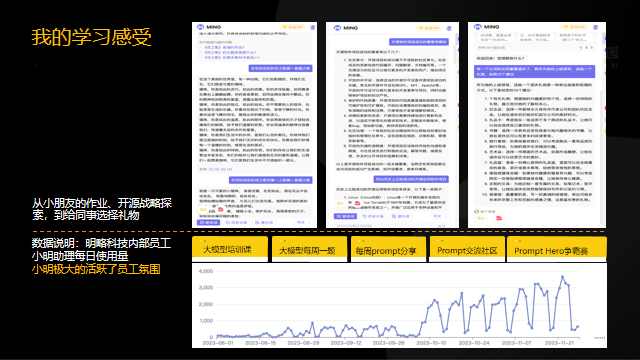
2023的10月,公司还举办了黑客马拉松大赛,我在场上向大家分享了十一期间使用大模型的经历,包括带着女儿用GPT写作业,用大模型思考公司战略,以及向大模型询问为退休同事准备礼物的建议,大模型的确给了我很多启发。我把使用案例分享给团队后,大家都惊讶地发现“小明助理”的用途如此广泛。今年,公司员工已经做到了广泛使用大模型,平均每个员工一天使用10次以上,大家不仅可以用GPT解决工作生活中遇到的一些问题,甚至可以放到自己的生产环境中用于提升生产效率,可以说,公司团队绝大多数的同学都已经拿到大模型的船票。

大家都很容易理解函数公式y=f(x)。大模型本质上就是一个函数,就是要设计、训练、学习出来一个函数。人工智能大模型领域常见的几种任务,比如语音识别,就是把一个声音的波形文件转化成一段文字,语音识别的函数x就是波形文件,y就是转写的文字。比如图像识别,图像识别的函数x就是照片,更高级的函数x可能是视频,它的y就是识别的任务目标。GPT其实也是一个函数,GPT的x就是Prompt,y就是给予你的回复,GPT本质上仍然是一个函数。从这个角度看,所有的人工智能都是一个函数。

大家在中学期间学习的第一个函数就是线性函数,y=ax+b,当你知道函数过的两个点,就可以得出a和b。将这个函数解出来之后,再带进去一个新的x,就可以直接求出y了,这是我们学函数的核心目的,找出x和y之间的关系,这也是今天AI在做的事情。AI就是我们做任何一个人工智能领域的任务,这个任务本身就是一个函数。这里面的(1,2)和(-1,6)是什么?就是训练的数据。

当然,GPT的函数要比以往的函数复杂很多,现在全世界最火的语言模型是GPT3.5和GPT4.0,GPT3.5有1750亿个参数,GPT4.0估计有上万亿个参数,这个参数就是线性函数里面的a和b。由此可见,GPT非常厉害的,它列了一个有千亿甚至上万亿个参数的函数,然后代入了大量的数据和点,最后把里面的参数解了出来。
我认为OpenAI是一家非常伟大的公司。OpenAI公司的创始人是Ilya,之后是前YC的总裁SamAltman,很多人在讨论,到底是Ilya重要还是Altman重要,因为OpenAI的核心算法都是Ilya带着研发团队做的,但是我认为Altman更重要一些,因为他解决了一个核心问题,即钱的问题。解一个万亿参数的方程,少则几千万美金,多则几亿美金。Altman的伟大之处,在于他可以让有钱的投资人敢于投资未知的事业,并且最终将方程式解了出来,这是一个改变世界、改变人类的伟大发明。

回到企业视角,明略科技是做ToB业务的,在同企业CEO、CIO、CMO聊天的时候,我发现大家对于大模型的出现都感到很兴奋,很多公司都建立了人工智能小分队,但尝试几次后发现效果并不理想。有一些人认为是因为国内的模型不行,他们尝试使用国外的,结果也并不好。我认为,一个想真正落地大模型的企业,如果还保持着上述思路,你与大模型就今生无缘了,因为大模型并不是参数越多,推理能力越强,越能解决自身的业务问题的。
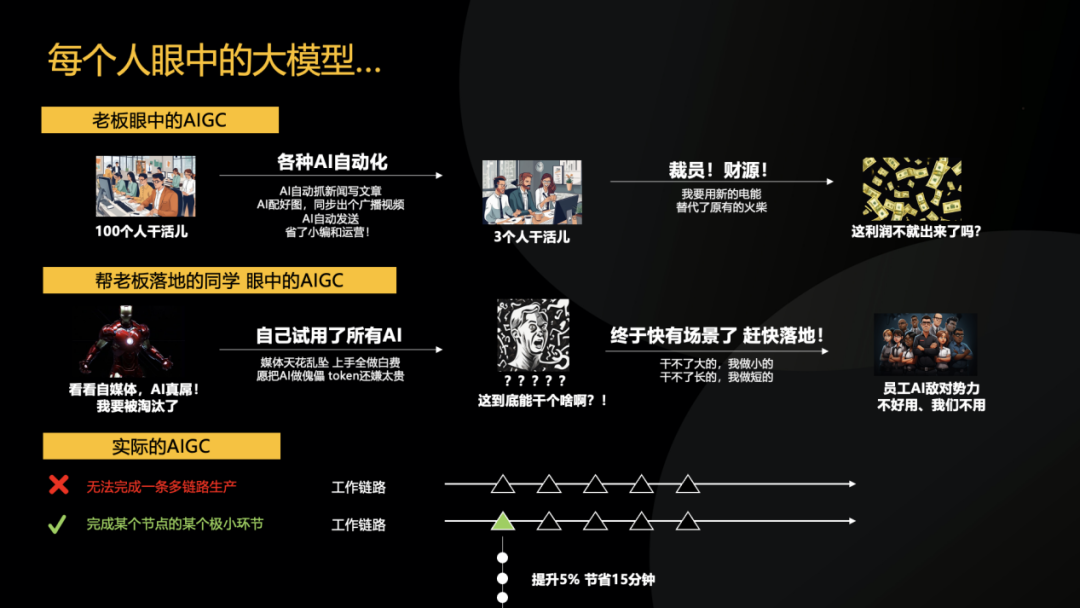
现在,OpenAI已经把参数做得非常高了,它拥有的是互联网上的通识知识,如果训练得足够好,它可以拥有清华、北大优秀本科毕业生同等的认知能力。但即使拥有了这种认知能力,就能确保大数据在企业中可以做好很多工作?答案是否定的。实际上,现实生活中很多优秀的本科毕业生在企业里发挥的作用并不理想,这是我们需要特别思考的。

值得注意的是,并不是模型的参数决定了它是否能在工作中有效转化成生产力。有一些任务,即使用很小参数的模型也能解决,还有很多的问题,即使发展到GPT7.0阶段也未必能解决。GPT3.5、GPT4.0的参数一直在上升,其主要目的在于自身迭代,要持续更新自身的核心能力。
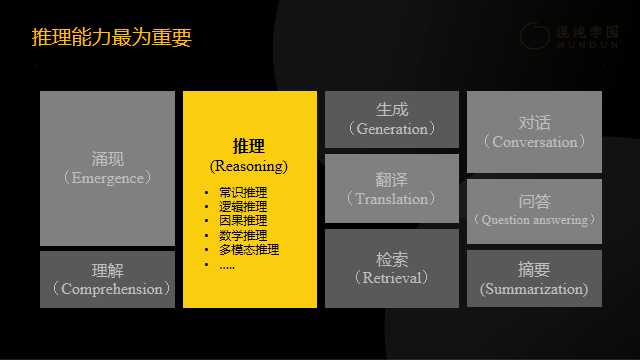

在同清华大学计算机系教授、智谱AI首席科学家唐杰老师聊天的时候,我提出了一个问题,智谱AI需要在哪方面着重加强,才能追赶上OpenAI?唐杰老师的回答是加强推理能力。推理能力是什么?其实,人类所有的智慧工作都可以称之为推理能力。当不知道一个模型好坏的时候,我建议大家可以向大模型提出一个问题进行检测,“美国的哪一个州跟其他的州不接壤”,这个问题的正确答案是阿拉斯加和夏威夷,它需要大数据知道美国的地理情况以及州和州之间的关系,但是很多模型的答案都是答非所问。这方面,国外LLaMA2等几个开源模型做得还比较好。
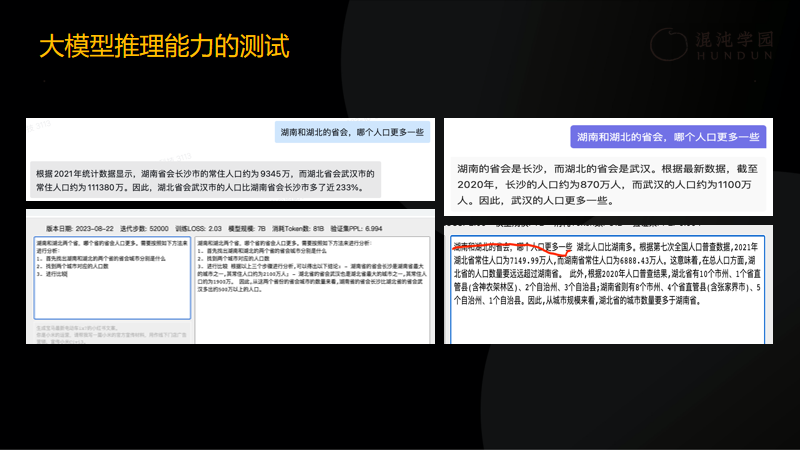
难道国内的大模型无法使用?我的答案是可以使用。比如人们向大模型提出问题,“湖南和湖北这两个省会,哪个人口更多一些”,国内的大模型往往会卡住,因为它根本没有理解这句话的意思,但如果通过操作把它的CoT能力调出来,大模型就有能力将答案推理出来。这如同一名新员工刚刚入职一样,只要公司给它的任务拆得足够细,他就能干好,甚至完成的情况不比清华、北大的毕业生差。我深切地感到,大模型的学习、发展和应用的过程,同人类从小的学习发展过程非常相像,两者是完全可以类比的。
我们讲大模型的迭代能力,就是要提高它的推理能力,而推理的过程需要信息。今天人们想将大模型应用到公司之中,但是大模型并不知道公司原有的生产资料和信息系统。人们花费大量资金,要解决的问题是什么?是它想不断地学习知识,从而提高自己的推理能力,它的最终形态是模型,而不是信息。它在企业中的价值是提供一个好的模。
爱游戏电子官网